

こんにちは!
前回に一つづきETECクラス2の試験対策です。今回のテーマは「プロセッサコア」です。
内容が多いのでどうしても長くなってしまいますが、試験を受ける上で覚えておくべきポイントに絞ってお伝えします。
できれば全部読んで欲しいですが気になる部分だけでも大丈夫です!
では早速内容に入っていきましょう。

MPUと命令の実行
まずはMPUと命令の実行についてです。ここでよく聞かれるのがMPUの役割と命令実行までの流れです。
この二つは絶対に押さえておくべきポイントなのでしっかり説明します。
MPUって?
MPU(Micro Processing Unit)は、組み込みシステムの演算と制御を担当する装置です。
役割的にはCPU(Central Processing Unit)と同じですが、一つのICにまとめられることが多いのでMPUとして区別されています。
ETECではMPUという単語で出てきますがCPUとして考えても問題ありません。
MPUは何をするの?
これは先ほど書いた通り演算と制御です。
もう少し詳しくみてみましょう。
まず演算です。
演算には加算や減算などの算術演算に加えて、ANDやORなどの論理演算が含まれます。
これらの演算もMPUが行います。
次に制御です。
MPUはメモリに格納されているプログラムにしたがって記憶装置などの他の装置を制御しながら命令を実行します。
この他の装置を制御する部分のことでです。
命令の実行の流れ
次に命令の実行の流れを説明します。ここは問題でも結構聞かれるのでしっかり覚えておきましょう。
①MPUがプログラムカウンタから次に実行する命令のアドレスから命令をを取り出し、命令レジスタに格納する
②命令レジスタに格納された命令を解読(デコード)する
③解読された命令が実行される。
この流れを覚えておけば大丈夫です。
- プログラムカウンタ ‥ 次に実行するべき命令のアドレスが格納されている
(命令自体が格納されているわけではない) - 命令レジスタ ‥ 命令が格納されている(プログラムカウンタのアドレスから取り出された命令)
命令の種類
命令は大きく6種類に分けることができます。ETECクラス2では命令の種類ごとの特徴を聞かれることもあるので大変ですがしっかり覚えましょう。
データ転送命令
データ転送命令はデータをメモリ-レジスタ間、またはレジスタ間で転送する命令です。
以下の3つに分類されます。
- ロード命令 : メモリからレジスタに転送
- ストア命令 : レジスタからメモリに転送
- ムーブ命令 : レジスタ間で転送
算術演算命令
これは名前の通り算術演算を行う命令です。説明不要かと思いますが以下の4つがあります。
- 加算命令
- 減算命令
- 乗算命令
- 除算命令
論理演算命令
これも名前の通りです。論理演算を行う命令です。
以下の4つです。
- AND命令
- OR命令
- NOT命令
- XOR命令
比較命令
これまた名前の通りです。二つの値を比較して大きい、または小さいを比較する命令がこれです。
制御転送命令
プログラムの実行フローを制御する命令です。以下の二つがその例です。
- ジャンプ命令 : 指定されたプログラムの位置に制御を移す(goto文など)
- 条件分岐命令 : 条件が真の場合のみ指定された位置に制御を移す(if文など)
特殊命令
システム制御など上に挙げた命令に分類されないものです。
- 割り込み制御命令 : イベントに応答して現在実行中のプログラムを停止して割り込み処理を行う
- ノーオペレーション命令 : 何もしない命令。タイミングの調整などに使用されます。
ETECクラス2の試験範囲で覚えておいた方がいい命令はこのくらいです。数は多く見えますが、名前からわかるものも多いのでそこまで苦労はしないと思います。
感覚ですがロード命令やストア命令などデータ転送命令について聞かれることが多いです。
レジスタってなに?
先ほどのデータ転送命令で、メモリからレジスタへ転送、レジスタからメモリへ転送と書きましたがレジスタとは何なのでしょうか。
レジスタは簡単にいうと記憶領域です。もう少し具体的にいうとMPUの内部にある小さな記憶領域で高速にアクセスできるように設計されています。
レジスタは次のような用途で使用されます。
- データや命令の一時的な格納
- 計算結果の保持
- プログラムの実行中に使用されるアドレス
レジスタの種類
試験対策として覚えておくべきレジスタの種類を解説します。
専門レジスタ
ある特定の用途に使用されるレジスタです。次のようなものが専門レジスタの例として挙げられます。
- プログラムカウンタ : 次に実行する命令のアドレスが格納
- スタックポインタ : 最後にアクセスされたスタックのアドレスを格納
- フラグレジスタ : 演算の結果に基づいて設定されるビットフィールド。ゼロやオーバーフローなどのフラグ
汎用レジスタ
専門レジスタとは反対に様々なものを格納しておくレジスタです。データ操作であったり一時的なデータの保存に使用されます。
汎用レジスタは算術演算やデータ転送命令によく使用されます。
その他のレジスタ
専門レジスタや汎用レジスタには分類されませんが、試験で聞かれることのあるレジスタを紹介します。
それぞれ詳しくは説明しませんがポイントだけ紹介します。
気になる方は調べてみてください。
- シフトレジスタ : パラレル転送方式とシリアルデータ転送方式の変換に用いられるレジスタ
パラレル転送方式だと通信回線で使用できないためシリアルデータ転送方式に変換する
必要があります。 - アキュムレータ : ALU(算術論理演算回路)の演算結果などを一時的に保持するレジスタ。汎用レジスタに
分類されることもあります。
命令とアドレス
命令はメモリに格納されているため、アドレスから命令を取り出して実行する必要があります。ここではまず実効アドレスについて説明します。
実効アドレスとは?
そもそも命令は命令コードとオペランドから構成されます。命令コードには命令の種類が書かれていて、オペランドには実効アドレスが含まれています。
実行アドレスが示す先に扱うデータが格納されています。
このアドレス(実効アドレス)の指定方法が複数あるため覚える必要があります。
即値方式
命令内に対象となる値を直接指定する方式です。アドレスではなく値を直接指定します。
直接アドレス方式
オペランド部に実行アドレスがそのまま示されている方式です。なのでこのアドレスの先に対象データが格納されています。
間接アドレス方式
オペランド部に実効アドレスのアドレスが示されている方式です。
オペランド部に書かれたアドレス → そのアドレスに書かれたアドレス → 対象データ
なので間接アドレス方式と呼ばれています。
インデックスアドレス方式
オペランド部にインデックスレジスタがあり、オペランド部に書かれたアドレスにインデックスレジスタに格納されている数字を足したものが実効アドレスになる方式です。
例えば、オペランド部に書かれたアドレスが1000でインデックスレジスタに格納された数字が10の場合の実効アドレスは、1000 + 10 = 1010です。
なのでアドレス1010を見に行くと対象データが格納されています。
ベースアドレス方式
ベースレジスタにオペランド部のアドレスを足したものが実効アドレスとなる方式です。
ベースレジスタにはプログラムの先頭アドレスが格納されています。ここで注意したいのが、インデックスレジスタはオペランド部についていたのに対して、ベースレジスタはそうではないということです。
ベースアドレス方式のオペランド部にはアドレスしか書いていないので、インデックスアドレス方式と混ざらないようにしましょう。
以上がETECクラス2試験の範囲で覚えておくべき実効アドレス方式です。
バス
次はバスについてです。バスはMPUがメモリなど他の装置と命令やデータをやり取りする際の伝送路のことです。
MPUは通常3種類のバスを制御してやりとりを行います。なのでここではその3種類のバスについて説明します。
バスの種類
先ほども書いたようにバスは伝送路なので、何をやりとりする時に使うのかをしっかりと区別しましょう。
データバス
データバスはMPUとメモリの間でデータや命令をやりとりする際に使用されます。
データバスのビット幅によって一度に転送できるデータ量が決まります。ビット幅が32ビットの場合は一度に32ビットまでのデータを転送することができます。
アドレスバス
アドレスバスはMPUからメモリへアドレスを転送するバスです。
アドレスバスのビット幅でアクセス可能なメモリの容量が決定します。例えば、アドレスバスのビット幅が16ビットの場合アクセス可能なメモリの容量は2^16 = 65536バイトです。
コントロールバス
コントロールバスは、データ転送のタイミングなどの制御信号をやりとりするバスです。
これらの3種類のバス(データバス、アドレスバス、コントロールバス)を内部バスと言います。
外部バス
内部バスがメモリとのやりとりだったのに対して、周辺装置とのやりとりに使用するバスを外部バスと言います。
外部バスの代表例がUSB(Universal Serial Bus)です。
バスの制御
ここまでで説明した通り、コンピュータの内部では各装置同士がバスを通して命令やデータをやりとりしています。
これらの装置のうち自分自身でバスを制御してデータ転送できる装置をバスマスタと言います。
バスマスタはデータ転送の開始などを自ら制御することができます。
それに対して、バスマスタの命令によって動くのがバススレーブです。
バスマスタとバススレーブという語句は問題文中や選択肢に出てくることもあるので頭に入れておきましょう。
そして一つ補足です。
複数のバスマスタが同じバスに接続されていた場合、同時にバスを使おうとしてしまう可能性があります。
それを防ぐためにバスマスタを制御する(どのバスマスタがバスを使えるのかを決定する)のがバスアービタです。
たまに聞かれることもあるので覚えておいて損はないと思います。
RISCとCISC
MPUのアーキテクチャは大きくRISCとCISCに分けることができます。ここではこの二つのアーキテクチャの特徴を説明します。
CISC(Complex Instruction Set Computer)
CISCは日本語に直訳すると複雑な命令セットを持つコンピュータです。
コンピュータが実効できる命令は、命令セットに入っている命令だけです。なので命令セットの数が多ければ多いほど実効できる処理が増えます。
CISCはどんな命令でも実効できることを目指してより多くの命令セットをコンピュータに持たせようとするアーキテクチャ(設計思想)です。
なので対応できる命令は多いです。しかし命令セットを多く持たせる分ハードウェアも複雑になり消費電力が大きくなるなどの問題もあります。
CICSではマイクロプラグラム制御方式が採用されることが多いです。この方式はある命令をそれより小さい命令(マイクロ命令)の組み合わせで表現する方式です。
なので命令を書き換える際は、このパーツ(マイクロ命令)を書き換えるだけで済みます。
RISC(Reduced Instruction Set Computer)
CISCに対して出てきたアーキテクチャがRISCです。先ほど書いたようにCISCにはできる限り多くの命令セットを持たせてより多くの命令を処理できるようにしました。
しかし実際プログラム中で指示される命令は一部しかなく、そんなに多くの命令セットは必要ありません。
なので頻繁に指示される命令だけを命令セットに入れて、シンプルな構成を目指すのがRISCです。
RISCでは命令の数を必要最小限にしていて、しかも全ての命令が固定長の単純なものです。
そのためパイプライン制御に適しています
RISCとCISCについては、このような流れで出てきた設計思想だということがわかっていれば大丈夫です。
その他のアーキテクチャ
MPUのアーキテクチャとしてはRISCとCISCが代表ですが、他にもいくつか紹介しておきます。
先にポイントをいうと、これから紹介するアーキテクチャは英語で覚えておくと意味が理解しやすいと思います。
- SISD(Single Instruction, Single Data) ‥ 一つの命令で一つのデータを取り扱う
- SIMD(Single Instruction, Multiple Data) ‥ 一つの命令で複数のデータを扱う
- MISD(Multiple Instruction, Single Data) ‥ 複数の命令が同一データを扱う
- MIMD(Multiple Instruction, Multiple Data) ‥ 複数のデータを別々の命令が扱う
組み合わせの問題なので覚えるのに苦労はしないはずです!問題で聞かれることもあるので頭の片隅に入れておいてください!
コプロセッサ
組み込みシステムにおいて、MPUの負荷軽減や処理の効率を上げるためにある処理専門のプロセッサを使用することがあります。
これらのプロセッサはMPUの補助の役割を果たすことからコプロセッサと呼ばれます。
どの分野でもそうですが、英語の頭文字を使う単語が多く出てきます。そういうものは英語で覚えることを意識してみてください。
覚えやすさが全然違います。
(先ほども書きましたが大事なのでもう一度書きました。しつこくてすみません。。。)
では本題に戻ってコプロセッサを紹介します。
- DSP(Digital Signal Processor) ‥ デジタル信号処理用のプロセッサ
- GPU(Graphics Processing Unit) ‥ 画像データ処理用のプロセッサ
- FPU(Floating-Point Unit) ‥ 浮動小数点数演算を行うようのプロセッサ
全て英語で覚えていれば暗記の必要もないと思います。
パイプライン処理とスーパースカラ
MPUのスループット向上のための方法としてパイプライン処理があります。
パイプライン処理は問題でもよく聞かれるものなのでしっかり理解しましょう。とは言ってもそんなに難しいものでもないので大丈夫です。
パイプライン処理とは
MPU内部での命令の実行は先ほど書いたように、取り出しや解読などいくつかのステップで処理されます。
このステップを並行して実行するのがパイプライン処理です。
文字で見てもわかりづらいと思うので図解します!
パイプライン処理なしの場合

パイプライン処理なしの場合に二つ命令を実行しようとすると、一つの命令がフェッチからレジスタ格納まで全て終わってから二つ目の命令の処理に入ります。
例えば一つのステップに1秒(1命令で5秒)かかる場合、二つの命令にかかる時間は10秒です。
パイプライン処理ありの場合
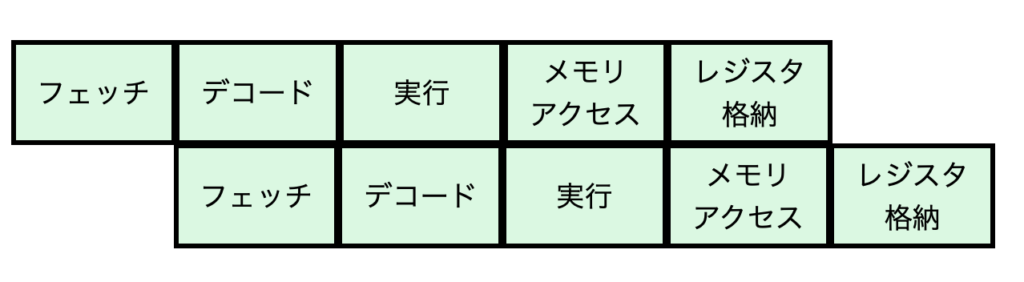
パイプライン処理のイメージ図がこれです。一つ目の命令のフェッチが終わったら二つ目の命令のフェッチを始めます。
先ほどの例と同様に1ステップ1秒(1命令5秒)かかる場合、二つの命令の実行時間は6秒です。
スーパースカラ
スーパースカラはパイプライン処理をもっと強力にしたものです。言葉で書くより図で見た方がわかりやすいと思うので見てください。
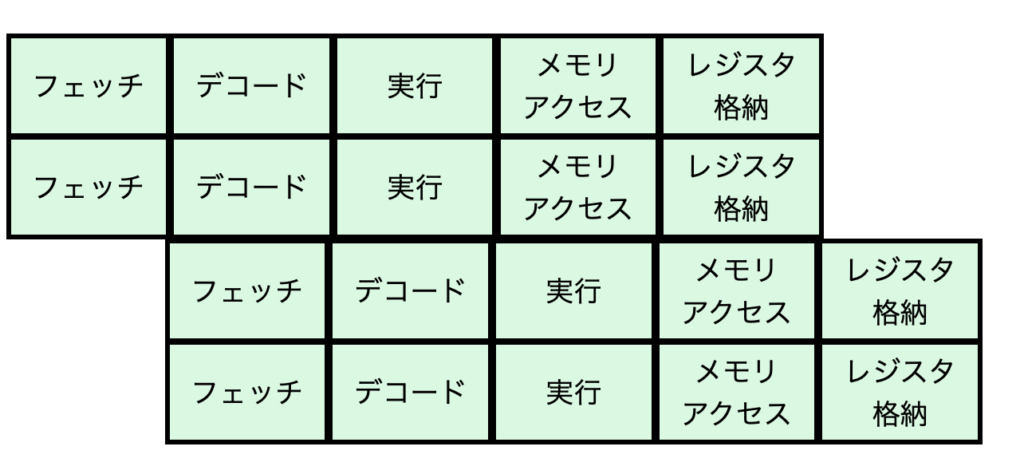
スーパースカラのイメージはこれです。複数の命令を同時に実行できます。
まとめ
今回は盛りだくさんでしたがプロセッサについてまとめました。特に重要なポイントだけ説明したので細かい部分は自分でも調べてみてください!








コメント